Proceedings 1th International Conference on Language Resources & Evaluation, Granada, 28-30 Mey 1998, edited by A.Rubio, N.Gallardo, R.Castro, A. Tejada, pp 51-54.
Evaluating various spoken dialogue systems with a single questionnaire:
Analysis of the ELSNET Olympics
Els den Os1 & Gerrit Bloothooft2
Abstract
At Eurospeech ’97 Elsnet provided the possibility for participants to test ten different spoken dialogue systems. After each test, participants were asked to complete a questionnaire (18 questions). This questionnaire was designed to assess the major properties of the spoken dialogue systems in a system-independent way. The total number of completed evaluation forms returned was 255, and for eight of the ten systems the number was large enough to permit meaningful statistical processing. A factor analyses was performed on the pooled data; the five main factors explained 75% of the total variance. Three of these five factors could be interpreted to reflect user opinions on (1) general appreciation, (2) functional capabilities of the system, (3) intelligibility of the output speech, while two were user-oriented: (4) proficiency in the system’s language, and (5) familiarity with spoken dialogue systems. Comparable sets of main factors were also obtained in separate factor analyses on the data for each system. This indicates that the first three main factors play a dominant role in the user's opinion of a spoken dialogue system, independently of the complexity or purpose of the system and independently of the user's knowledge of the system's language or the user's familiarity with this kind of information service. Some recommendations are given for the design of subjective evaluation of spoken dialogue systems by means of questionnaires.
1. Introduction
As the number of spoken dialogue systems is growing, the need to evaluate these systems becomes important. Since spoken dialogue systems are complex and include a combination of speech recognition, natural language processing, dialogue management, and speech synthesis, assessment of the complete system is not a simple task. Objective evaluation may address the length of the dialogue, the number of turns, the number of diagnostic turns by the system, the number of speech recognition errors, the number of successful database queries, and so on. Besides this objective evaluation, subjective assessment can be used to address the perceived quality of the dialogue system (Walker et al., 1997). The only way to investigate the perceived quality of a system is by asking users questions about it. These questions may be related to the overall acceptability of the system or may have a more diagnostic purpose in order to address specific features of a system. In the first case it is more appropriate to ask open questions like "How did you get along?" and "What do you think of this system?" In the second case it is more appropriate to use Likert scales (e.g. "The system did understand me well": I fully agree [1]-[2]-[3]-[4]-[5] I fully disagree). In this paper we concentrate on the latter type of diagnostic evaluation.
At the ELSNET Olympics, Eurospeech '97 participants had the unique opportunity to test ten different dialogue systems. All systems were evaluated using the same questionnaire. For naïve subjects it will probably be difficult to answer diagnostic questions. However, the Eurospeech population may be considered capable of answering these types of questions about spoken dialogue systems. In this paper we investigate whether different spoken dialogue systems can be assessed by a single questionnaire. This is only possible if the questionnaire (and the individual questions) address relevant features that are present in all systems. If that proves to be the case, we may hope to be able to compare subjective evaluations of dialogue systems for different tasks. Even more importantly: we would then be in a position to transfer knowledge and experience gained with one system to speed up the development of other systems.
2. The questionnaire
The ten systems that participated in the Elsnet Olympics differed in task, lexicon size, type of speech recognition, dialogue design, availability of barge-in, type of system speech and language. Our hypothesis was that irrespective of these differences it is still possible to assess systems subjectively by putting the focus on whether systems do what they claim to do from the perspective of the user. Therefore, the questions were formulated in a general way (see table 1 for the questionnaire). Most questions were of the closed type using a Likert scale, few other ones were of the open type in order to be able to interpret the meaning of the answers to the closed questions more clearly. Next to the questions related to the spoken dialogue systems, two questions were included addressing the users’ proficiency in the system’s language and the familiarity of the user with spoken dialogue systems, to see whether these factors influence the diagnostic evaluation.
3. The systems
Two of the eight systems could not be tested properly. The Aizula system (Japan) (Ward, 1996) was not an information system but a demonstration of simulated back-channel feedback. The Actis system (KDD, Japan) provides information about area codes, country codes and time differences between Japan and the destination of an international call. The lexicon covers the names of 300 countries and a thousand cities all over the world. Due to line problems the system was only tested a few times.
- Did
the system fulfil your expectations |
. | yes /no /in part | |||||
-
Please give your opinion on the following aspects |
. | . | |||||
| . | . | POOR | GOOD | ||||
| . | * the functional possibilities of the system | 1 | 2 | 3 | 4 | 5 | |
* speech recognition |
1 | 2 | 3 | 4 | 5 | ||
| * intelligibility of the system's speech | 1 | 2 | 3 | 4 | 5 | ||
| * wording of system's utterances | 1 | 2 | 3 | 4 | 5 | ||
| * overall dialogue structure | 1 | 2 | 3 | 4 | 5 | ||
| * the possibility to recover from system errors | 1 | 2 | 3 | 4 | 5 | ||
* appropriateness of the system's reactions |
1 | 2 | 3 | 4 | 5 | ||
| * length of the dialogue | 1 | 2 | 3 | 4 | 5 | ||
| * the system's error messages | 1 | 2 | 3 | 4 | 5 | ||
| * task completion | 1 | 2 | 3 | 4 | 5 | ||
| * your overall satisfaction | 1 | 2 | 3 | 4 | 5 | ||
- Please list strong points of the system |
. | ||||||
| - Please list weak points of the system | . | ||||||
- What is your mother tongue? |
. | ||||||
| . | . | POOR | NATIVE | ||||
- What is your proficiency in the system's language |
. | 1 | 2 | 3 | 4 | 5 | |
. |
. | LITTLE | MUCH | ||||
- Are you acquainted with spoken dialogue systems |
. | 1 | 2 | 3 | 4 | 5 | |
| Please use the space
below for additional comments . . |
|||||||
Table 1: Text of the questionnaire
The remaining eight information systems were:
Jupiter (MIT, Cambridge MA, USA) (Zue et al., 1997): The version of Jupiter used at the ELSNET Olympics was a US English conversational system that gives current weather forecasts over the telephone for over 500 cities worldwide. The system can answer queries about general weather forecasts, temperature, humidity, wind speed, sunrise/sunset times, and weather alerts (such as flooding and hurricanes). It obtains its weather information from Web sources. Jupiter has a vocabulary of 1400 words, and will soon be able to handle calls in German, Mandarin, and Spanish. It uses text-to-speech synthesis for output speech.
STACC (University of Granada, Spain) (Rubio et al., 1997): This system-driven service allows students to consult their marks. Students have to enter one of two degrees and one of six courses they want to consult, and say their full name as well as an eight-digit identification number. When the name and identification number match, the system provides the required mark. The lexicon contains about 300 words.
O-tel (University of Maribor, Slovenia). This automatic reverse directory service can handle Slovenian, English, and German. The user enters digits in one of these languages; the digits must be separated by short pauses, since isolated-word recognition is used. The system repeats each digit, and when a digit is not recognized correctly, the caller can erase it. The most distinguishing feature of this system is that it has talk-through capability. The output is given by word-based synthesis.
EVAR (University of Erlangen, Germany) (Boros et al., 1997): Developed within the Sundial project, this system provides information on German Intercity timetables. It is run mainly for research purposes. Research emphasis is on the (relatively free) dialogue, on robust recognition, parsing of spontaneous speech and detection of out-of-vocabulary words. The dialogue manager can cope with anaphora and ellipses, and has a variety of recovery strategies for unusual situations. The user can always go back and change information. The system has a vocabulary of 1600 words, as well as a spelling mode for
when standard dialogue strategies fail.
Dialogos/Italian Arise (CSELT, Torino, Italy) (Albesano et al., 1997): Like the three systems below, this continuous-speech dialogue system forms part of the Arise project, a European research project partly funded by the EC under the LE sector of the Fourth Framework Telematics Application Programme. It has a vocabulary of 3,500 words, including 3,000 Italian station names. The dialogue module interprets the content of the user's utterances by taking into account both previous utterances and data pertaining to the application. The system can support different clarification and correction subdialogues, and is able to detect repairs initiated by the user. It uses text-to-speech synthesis for output speech.
LIMSI Arise (Orsay, France) (Lamel et al., 1996): This system provides information on train schedules, fares, reductions, and services in French. It uses continuous speech recognition with task-dependent acoustic models. The lexicon contains about 1500 words, 680 of which are station names. It is possible to interrupt system prompts (barge-in); speech output is handled by synthesis, through concatenation of about 2000 prerecorded units. The system uses a very open mixed-initiative dialogue: the caller is free to ask any question at any time. The system asks the user to provide the information it needs for database access, but can deal with the caller providing different information.
IRIT Arise (Toulouse, France) : This system uses speech recognition and dialogue management technology developed by Philips. The lexicon contains 1500 words (500 of which are station names). It is a conversational system, with concatenation of prerecorded speech being used for the system's output.
Dutch Arise (NS/OVR, Philips, KPN Research, University of Nijmegen, the Netherlands): This conversational system has a lexicon of 1380 words (680 station names). Its speech recognition component uses context-dependent acoustic models (triphones). The system has been trained by more than 11,000 dialogues, and uses concatenation of prerecorded units for speech output.
4. Results
We analysed the data from the Likert scales by means of a factor analysis which was followed by varimax rotation for more easily interpretable links between questions and factors. Since only completed questionnaires could be used for factor analysis we had to discard quite a few questionnaires (see table 2). Some users did not encounter errors and consequently could not answer error-related questions, others failed to communicate meaningfully with a system and did not get any impression of details of the system's capacities, while some users simply forgot to turn the page of the questionnaire. There was no specific relation between a system and the type of missing questions, with the exception of the multi-lingual O-tel system for which some users failed to pass the language choice.
| . | Total |
Completed |
ARISE DUTCH |
24 |
16 |
ARISE ITALIAN |
33 |
23 |
ARISE IRIT |
33 |
30 |
ARISE LIMSI |
41 |
31 |
EVAR |
46 |
36 |
JUPITER |
114 |
78 |
O-TEL |
45 |
31 |
STACC |
18 |
10 |
TOTAL |
354 |
255 |
Table 2. Total number of questionnaires returned for each system and the total number of fully completed questionnaires used for factor analysis.
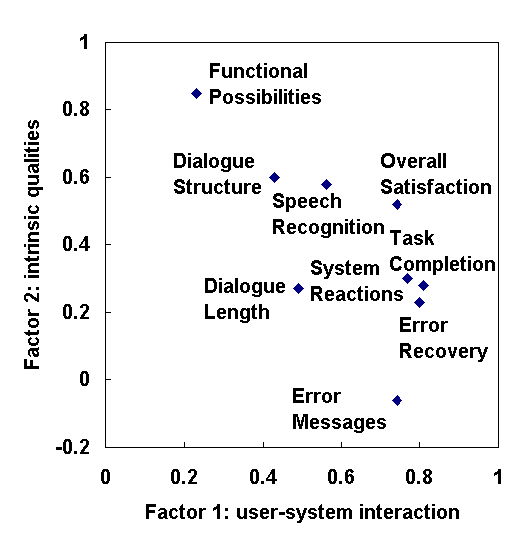
Table 3 shows the results of the factor analysis for the pooled data. Five main factors can be distinguished, which together explain 75% of the total variance. The first three factors are related to system properties, the last two are user-oriented. The first factor refers to the general appreciation of a system and addresses how a user perceives the interaction with the system. Questions about overall satisfaction, task completion, error recovery and error messages have their main loading on this factor.
| Question | 1 |
2 |
3 |
4 |
5 |
| 1 GENERALAPPRECIATION | . | ||||
| Task completion | .81 |
.28 |
-.00 |
.14 |
-.08 |
| Error recovery | .80 |
.23 |
.09 |
-.12 |
.03 |
| Appropriate reactions | .77 |
.30 |
.17 |
.04 |
.12 |
| Error messages | .74 |
-.06 |
.33 |
-.10 |
.22 |
| Overall satisfaction | .74 |
.52 |
.11 |
-.00 |
-.01 |
| Speech recognition | .56 |
.58 |
.10 |
.24 |
-.03 |
| Dialogue length | .49 |
.27 |
.37 |
-.25 |
.02 |
| 2 FUNCTIONAL CAPABILITIES | . | ||||
| Functional possibilities | .23 |
.85 |
.14 |
-.02 |
.07 |
| Dialogue structure | .43 |
.60 |
.24 |
-.27 |
.17 |
| 3 SYSTEM SPEECH | . | ||||
| Speech intelligibility | .01 |
.09 |
.81 |
.23 |
-.16 |
| Wording of utterances | .33 |
.19 |
.73 |
-.09 |
.04 |
| 4 USER's LANGUAGE PROFICIENCY | .00 |
-.02 |
.10 |
.88 |
.14 |
| 5 USER's FAMILIARITY WITH DIALOGUE SYSTEMS | .08 |
.09 |
-.10 |
.14 |
.93 |
Table 3. Loadings of all closed questions on the first five factors after factor analysis (followed by varimax rotation). Boldface typed numbers show loadings that exceed 0.70. Factors 4 and 5 correspond to a single question.
The second factor refers to the functional capability of the system, i.e. what is the purpose of the system? It can be noticed that most questions that are mentioned under the first two factors have their major loadings on both factors 1 and 2, which implies that most of these questions measure some combination of general appreciation and the functional capabilities of the system. The third factor deals with properties of the system prompts and output speech. These three factors are independent dimensions in the user’s assessment of a system.
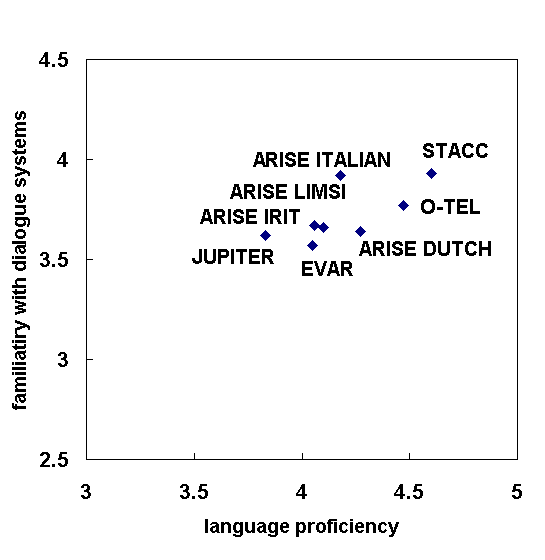
The fourth and fifth factors (language proficiency of the user and the familiarity with spoken dialogue systems) are user-related. Interestingly, there is no interaction between these user-oriented factors and the factors dealing with the assessment of system properties.
A proper factor analysis presupposes a single subject group evaluating all systems. Obviously, this could not be the case because of the different languages of the systems. We therefore also performed factor analyses on data for each of the systems separately. If the same factor pattern as for the pooled data shows up for the individual systems, this would support the general validity of the overall analysis. Table 4 summarizes the results of the separate analyses. For most questions the relation to the main factors was comparable for all systems. A slight complication was that the question on wording of the system utterances now got a separate factor for four systems, which in two cases was also related to the question on error messages. The question on dialogue structure loaded on factor 1 or factor 2, while the question on dialogue length was linked to various factors for the different systems. The scatter in the loadings of the latter questions over the factors in the pooled data obviously originates from system-dependent usage of these questions.
| Question | DUTCH |
LIMSI |
IRIT |
ITALIAN |
EVAR |
JUPITER |
O-TEL |
STACC |
. |
| Task completion | 1 | 1 | - | 1 | 1 | 1 | 1 | 2 | 1 |
| Error recovery | 1 | 1 | 1 | 1 | - | 7 | 1 | 1 | 1 |
| Appropriate reactions | 1 | 1 | - | 1 | 1 | 1 | 1 | 1 | 1 |
| Error messages | - | 1 | 6 | 1 | 6 | - | 1 | 1 | 1 |
| Overall satisfaction | 1 | 1 | 1 | 1 | 1 | 1 | - | 1 | 1 |
| Speech recognition | 8 | 1 | 1 | - | 1 | 1 | - | 8 | 1 |
| Functional possibilities | 2 | 2 | 1 | 2 | 2 | - | 2 | 2 | 2 |
| Speech intelligibility | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 |
| User's proficiency | - | 4 | 4 | 4 | 3 | 4 | 4 | 2 | 4 |
| User's familiarity | 2 | 5 | 5 | 5 | 5 | 5 | 5 | 3 | 5 |
| Wording of utterances | 6 | 2 | 6 | 3 | 6 | - | 3 | 6 | 6 |
| Dialogue structure | - | 2 | 1 | 2 | 6 | - | 2 | 1 | X |
| Dialogue length | 6 | 2 | 3 | - | - | - | 5 | 1 | X |
Table 4. Factor associations per question after separate factor analysis (and varimax rotation) per system. A question was associated with a factor when its loading exceeded .70 (otherwise - is inserted). The factor numbering follows Table 3, but higher numbers were introduced when for some system the factor pattern did not match the general pattern. The right column shows the most common factor per question.
| . | 1 |
2 |
3 |
4 |
5 |
| ARISE DUTCH | -.10 |
.50 |
.51 |
.27 |
-.42 |
| ARISE IRIT | .05 |
-.22 |
-.55 |
-.09 |
-.16 |
| ARISE ITALIAN | .79 |
.40 |
-.10 |
.17 |
.26 |
| ARISE LIMSI | -.50 |
.02 |
.72 |
-.03 |
.11 |
| EVAR | -.14 |
-.20 |
-.36 |
.11 |
-.23 |
| JUPITER | -.05 |
.20 |
-.17 |
-.31 |
-.10 |
| O-TEL | .12 |
-.82 |
.36 |
.17 |
.10 |
| STACC | .29 |
.58 |
.31 |
.97 |
-.03 |
Table 5. Average factor scores of the eight systems on the five main factors. Gray cells indicate significantly different values (p<.05) per factor. For factor 3 the marked group of three cells differ significantly from the values -.36 en -.51 only.
Finally, we present in Table 5 the average factor scores of the systems on the five main factors. Significancies of differences were determined by performing, per factor, an ANOVA on the raw factor scores, followed by Newman-Keuls posthoc analysis. The results are consistent with a description presented in Bloothooft & den Os (1997). Since each system more or less had its own user group, systematic scoring differences between these groups may have affected the average scores and hence the factor scores. This can happen even when the relative relations between questions are about the same for all groups, as shown in the present study. Therefore the average factor scores should be treated with some caution.
5. Discussion
In the subjective diagnostic evaluation of spoken dialogue systems we found that users distinguish three independent factors while judging these systems. These factors reflect three general features: (1) general appreciation of the system, (2) functional capabilities of the system and (3) quality of the output speech. Since these three factors were shown to be highly system independent, we recommend that they should get special attention in both the design and the subjective diagnostic evaluation of any system. However, since these factors refer to very general features, it remains to be seen whether answers to questions addressing these factors will be of help in designing improved systems. On the other hand, it is also questionable whether more detailed and system-specific questions would result in more useful responses, especially when the system is tested by non-experienced users. It may well happen that detailed questions are interpreted in terms of the three main factors presented.
Familiarity with dialogue systems and language proficiency of users did not interact with the assessment of the systems. This result supports the fundamental character of the main factors. They not only span the views of experts but also the experiences of users who are less proficient in the language and probably pose a critical test to the system, and they also span the assessment of users which are less familiar with these types of systems, their properties and their terminology. It is uncertain, however, whether this result extends from the Eurospeech population to the general public. In general it may be wise to include explicit questions on the user's knowledge of the functionality of a system.
Some of our questions were not always interpreted in the same way among different systems. These questions are related to important diagnostic features such as error messages, speech recognition, wording of system speech, dialogue structure, and dialogue length (see table 4). However, it is not always clear whether this system-dependent interpretation could have been avoided by a better phrasing of the questions. For instance, the question on speech recognition has a more precise meaning in an isolated word recogniser than in a system using continuous speech recognition where it is not always clear whether speech recognition or other parts of the system failed. In this case it probably does not make sense to improve the question. Even for experienced users it is often hard if not impossible to distinguish between failures due to speech recognition, to a wrongly designed dialogue structure, or to incomplete functionality of the application. This type of ambiguity does not hold, for instance, for the question on dialogue length. Among other things, dialogue length can be influenced by system utterances which are too long or provide too much information, by an inefficient design of the dialogue, or by speech recognition that is too slow. These causes can be addressed separately in a system-specific questionnaire. Because our questionnaire had to be applied to very different systems, the phrasing of the questions had to be general but we recommend a more precise phrasing in system-specific questionnaires.
References
Albesano, D., Baggia, P., Danieli, M., Gemello, R., Gerbino, E., & Rullent, C. (1997). A Robust System for Human-Machine Dialogue in Telephony-Based Applications. J. of Speech Technology 2, pp. 99-110.
Bloothooft, G. & den Os, E. (1997). The ELSNET Olympics. Testing Spoken Dialogue Systems at Eurospeech'97. ELSNews 6.5, pp. 1-3.
Boros, M., Aretoulaki, M., Gallwitz, F., Noeth, E., & Niemann, H. (1997). Semantic Processing of Out-of-Vocabulary Words in a Spoken Dialogue System. Proc. Eurospeech'97, Rhodes, pp. 1887-1890.
Lamel, L., Gauvain, J.L., Bennacef, S.K., Devillers, L., Foukia, S., Gangolf, J.J., & Rosset, S. (1996). Field Trials of a Telephone Service for Rail Travel Information. Proc. IEEE IVTTA-96, Basking Ridge, NJ, pp. 111-116, October. (also to appear in Speech Communication)
Rubio, A.J., García, P., Torre, I. de la, Segura, J., Díaz-Verdejo, J., Benítez, M.C., Sánchez, V., Peinado, A.M., & López-Córdoba, J.L. (1997). STACC: An Automatic Service for Information Access Using Continuous Speech Recognition Through Telephone Line. Proc. Eurospeech'97, Rhodes, pp. 1779-1782.
Walker, M.A., Litman, D., Kamm, C. & Abella, A. (1997) Paradise: A general framework for evaluating spoken dialogue agents. Proc. ACL/EACL 97, Madrid.
Ward, N. (1996). Using Prosodic Clues to Decide When to Produce Back-channel Utterances. Proc. ICSLP'96, Philadelphia, pp. 1728-1731.
Zue, V., Seneff, S., Glass, J., Hetherington, L., Hurley, E., Meng, H., Pao, C., Polifroni, J., Schloming, R., & Schmid, P. (1997). From Interface to Content: Translingual Access and Delivery of On-line Information. Proc. Eurospeech'97, Rhodes, pp. 2227-2230. Also http://www.sls.lcs.mit.edu/jupiter.
Additional figures from the oral presentation
Figure 1: Factor loadings of all closed questions on the first two factors, associated with user-system interaction and intrinsic qualities, respoectively
Figure 2: Factor scores of all systems on the first two factors, associated with user-system interaction and intrinsic qualities, respectively.

Figure 3: Factor scores of all systems on factor 1 and 3, associated with user-system interaction and system speech, respectively.

Figure 4: Factor scores of all systems on factor 2 and 3, associated with intrinsic qualities and system speech, respectively.
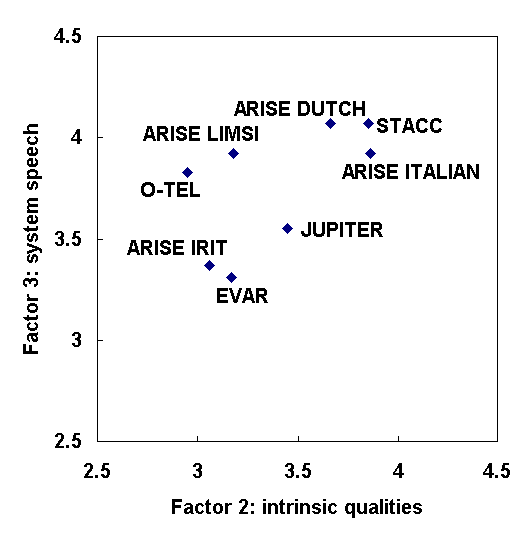
Figure 5: Average scores of all systems on the questions on the language proficiency of the user (horizontal axis) and on the user's familiaruty with dialogue systems (vertical axis).